|
Kommunikation und Synchronisation
ÜBERSICHT
1. Begriffe
2. Kooperationsformen
3. Kommunikationsmuster
4. Kommunikation und Synchronisation: Konzepte
5. Basisoperationen für den Nachrichtentransfer
6. Synchroner und asynchroner Nachrichtenaustausch
7. Verbindungslose- und verbindungsorientierte Kommunikation
8. End-to-End-Argumente
9. Quellen
1.
Begriffe
Sequentielles Programm: Eine
Liste von Anweisungen, die sequentiell ausgeführt werden.
Prozess: Die Ausführung
eines sequentiellen Programms
Nebenläufiges Programm:
Zwei oder mehr sequentielle Programme, die als nebenläufige
Prozesse ausgeführt werden. Hier ist Synchronisation
erforderlich. Man unterscheidet folgende zwei Fälle bei
nebenläufigen Prozessen: Prozesse nutzen einen gemeinsamen
Prozessor und Prozesse nutzen unterschiedliche Prozessoren,
d.h. werden echt parallel ausgeführt. Bei Prozessen,
die unterschiedliche Prozessoren benutzen, unterscheidet man
Multiprocessing, Parallel Processing und Distributed Processing.
Bei Multiprocessing haben die
Prozessoren gemeinsamen Speicher.
Unter Parallel Processing versteht
man Prozessoren, die keinen gemeinsamen Speicher haben aber
über ein schnelles, Interkonnektionsnetzwerk verbunden.
Falls Prozessoren keinen gemeinsamen
Speicher haben und über ein Rechnernetz (LAN, MAN, WAN)
miteinander verbunden sind, so spricht man von Distributed
Processing.
Kooperation: Wenn Prozesse zusammenarbeiten, um ein gemeinsames
Ziel zu errechen, so spricht man von Kooperation.
Konkurrenz: Prozesse konkurrieren
um die Benutzung von Ressourcen.
Kooperation und Konkurrenz schließen
einander nicht aus.
Kommunikation: Kommunikation
ist der Austausch von Information zwischen Prozessen.
Synchronisation: Prozesse synchronisieren
sich auf Ereignisse, wobei Prozesse Ereignisse herbeiführen
können. Prozesse können bis zum Eintritt eines Ereignisses
verzögert werden.
2. Kooperationsformen
2.1 Produzenten/Konsumenten-Systeme
Der Konsument nimmt Daten auf,
die vom Produzenten erzeugt wurden. Hier genügt ein unidirektionaler
Kanal.

2.2 Pipeline-Modell
Eine Pipeline kann man sich als
ein unidirektionalen Kanal vorstellen.
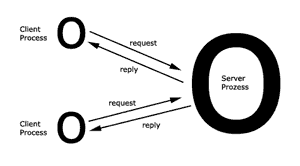
2.3 Client/Server-Modell
Der Server bietet seinen Service
einer Menge a priori unbekannter Klienten an. Service bezeichnet
die Software-Instanz, die auf einer oder mehreren Maschinen
ausgeführt wird. Der Server ist eine Maschine, die Service-Software
ausführt. Der Klient ist der Nutzer eines Services.
3. Kommunikationsmuster
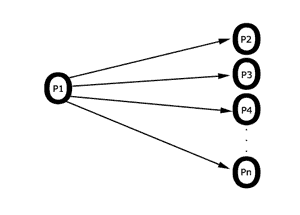
3.1 1-to-1
Senden an genau einen Prozess.

3.2 Rundsenden (broadcast)
Senden an alle Prozesse
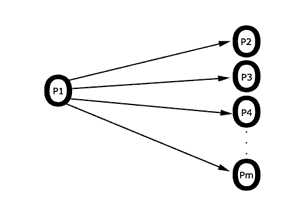
3.3 Mehrfachsenden (multicast)
Senden an eine Gruppe G von Prozessen.
Es gilt : 1 < |G| < n
4. Kommunikation und Synchronisation:
Konzepte
Es gibt zwei Möglichkeiten
Kommunikation und Synchronisation zu realisieren. Der erste
Ansatz ist mittels gemeinsamen Speicher. Techniken dazu sind
Semaphore, Monitore und Pfadausdrücke.
Der zweite Ansatz ist Kommunikation und Synchronisation mittels
Nachrichtenaustausch. Da gibt es die Konzepte von Nachrichten,
RPC, Rendezvous und virtuellem gemeinsamen Speicher.
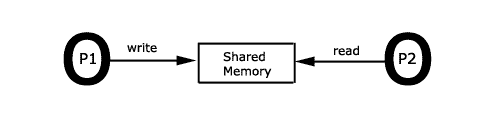
Beispiel: In dem oberen Beispiel findet die Kommunikation
durch Schreiben und Lesen des gemeinsamen Speichers statt.
Synchronisiert wird auf Zustandsänderungen des gemeinsamen
Speichers. Als Synchronisationskonzepte kommen hier zum Einsatz:
Semaphore, Monitore, Pfadausdrücke usw.
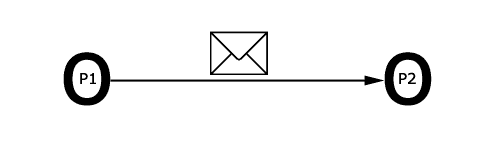
Beispiel: Kommunikation und Synchronisation findet durch den
Austausch von Nachrichten statt - Nachrichtenaustausch = Kommunikation
+ Synchronisation. Kommunikation durch das Senden und Empfangen
von Nachrichten. Synchronisiert wird auf Sende und Empfangsereignisse.
Wir verfolgen den Ansatz der
Kommunikation und Synchronisation mittels Nachrichtenaustausch.
Auf den Ansatz "gemeinsamer Speicher" wird hier
nicht näher eingegangen.
5. Basisoperationen für
den Nachrichtentransfer
Für den Nachrichtenstransfer
gibt es zwei Basisoperationen, nämlich send und receive.
send expression to destination
Die Nachricht enthält den
Wert von expression. Mit destination spezifiziert man das
Ziel oder die Ziele.
receive variable from source
Die Nachricht wird in variable
empfangen. Source spezifiziert, von welcher Quelle die Nachricht
kommen soll.
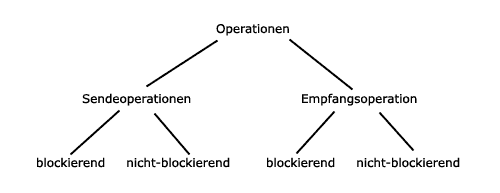
Aus der obigen Abbildung ist zu entnehmen, dass die Operationen
nochmals in blockierend und nicht-blockierend unterteilt werden.
Doch zuvor noch grundsätzliche
Gedanken. Wohin kann die Sendevariable kopiert werden?
Beispiel 1:
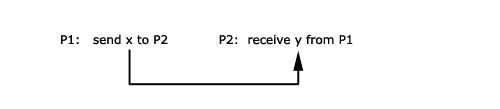
Beispiel 2:
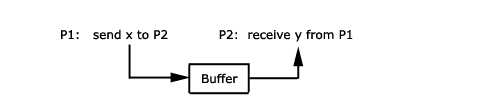
Die Beispiele zeigen zwei Möglichkeiten.
Beim ersten Beispiel wird die Sendevariable direkt in die
entsprechende Empfangsvariable kopiert. Das zweite Beispiel
zeigt den Fall, in der die Sendevariable in einen Puffer kopiert
wird.
nicht-blockierende Sendeoperation
Der Sender wird nur für die Dauer des Kopierens verzögert.
blockierende Sendeoperation
Der Sender wird so lange verzögert, bis die entsprechende
Empfangsanweisung ausgeführt wird.
blockierende Empfangsoperation
Der ausführende Prozess wird so lange blockiert, bis
Nachricht eingetroffen ist.
nicht-blockierende Empfangsoperation
Der ausführende Prozess wird keinesfalls blockiert. Hier
gibt es zwei Varianten.
Variante 1: Falls eine Nachricht vorhanden ist, wird sie empfangen,
sonst Return Code.
Variante 2: Receive signalisiert die Empfangsbereitschaft.
Wenn die Nachricht eintrifft, wird der Empfangsprozess unterbrochen.
6. Synchroner und asynchroner
Nachrichtenaustausch
6.1 Synchroner Nachrichtenaustausch
Beim synchroner Nachrichtenaustausch
benutzen Sender und Empfänger blockierende Sende- und
Empfangsoperationen. Wichtig ist, das hier keine Pufferung
notwendig ist. Denn die Nachricht kann direkt vom Senderadressraum
über das Netzwerk in den Empfängeradressraum kopiert
werden.
Woher weiß aber der Sender,
wann er Nachrichten senden kann bzw. eine Nachricht empfangen
wurde?
Protokoll1: send blockiert bis
Bestätigung für Nachricht empfangen wurde
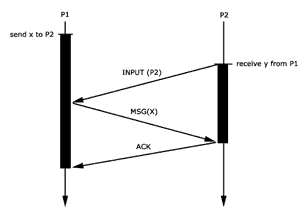
Prozess P1 und P2 tauschen synchron Nachrichten. Beide Operationen
sind blockierend. Durch die INPUT(P2) Nachricht, weiß
der Sender, dass er die Nachricht senden darf. Mit ACK bestätigt
P2 den Erhalt der Nachricht.
Protokoll 2: send blockiert bis
receive aufgerufen wurde
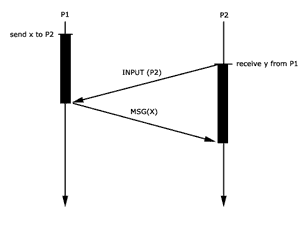
Bei Protokoll 2 fehlt die ACK, die Bestätigung für
den Erhalt der Nachricht.
6.2 Asynchroner Nachrichtenaustausch
Beim asynchronen Nachrichtenaustausch
benutzt mindestens einer der Prozesse eine nicht-blockierende
Sende- oder Empfangsoperation.
Protokoll 1:
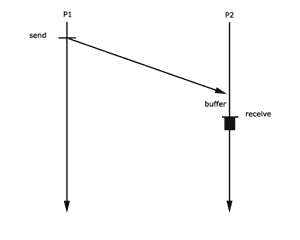
Damit asynchroner Nachrichtenaustausch
überhaupt funktioniert, ist prinzipiell unendlich großer
Puffer erforderlich. Das Protokoll 1 zeigt so einen Fall.
So ist es z.B. möglich, dass P1 mit send unendlich viele
Nachrichten in den Puffer schreibt. Aus diesem unendlich großen
Puffer kann sich P2 bedienen.
Protokoll 2:
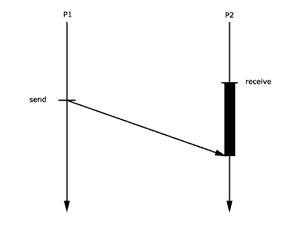
Es handelt sich hier um das selbe Protokoll wie Protokoll
1. Hier ist nur der Fall dargestellt, in der P2 auf eine Nachricht
wartet. Dies kann passieren, wenn der Puffer leer ist. In
dem Augenblick, nachdem P1 etwas in den Puffer geschrieben
hat, kann P2 die Nachricht auslesen und ist nicht mehr blockiert.
Man stelle sich den realistischen
Fall vor, in der Puffer endlich groß ist. Hier wird
der Sender bei vollem Puffer so lange blockiert, bis wieder
Speicher frei wird. Man spricht von pufferblockierendem Senden.
Ein einfaches Protokoll dazu
ist das Stop-and-wait-Protokoll. Der Puffer kann genau eine
Nachricht aufnehmen. Die Pufferung findet beim Empfänger
statt. Eine Verallgemeinerung des Stop-and-wait-Protokolls
ist der Fenstermechanismus.
Beschreibung des Stop-and-wait-Protokolls:
1. Wenn der Puffer leer ist,
so kann P1 die Nachricht in den Puffer kopieren und wird nicht
blockiert.
2. Falls P1 eine Nachricht senden
möchte und der Puffer nicht leer ist, wird er solange
blockiert, bis ein ACK von P2 eintrifft. Mit ACK signalisiert
P2, dass der Puffer überschrieben werden darf.
3. Falls Puffer belegt ist und
P2 empfangen möchte, so wird P2 nicht blockiert. Er muss
nur ein ACK an P1 schicken.
4. Falls Puffer leer ist und
P2 empfangen möchte, so wird P2 so lange blockiert bis
P1 eine Nachricht in den Puffer schreibt.
6.3 Synchroner vs. asynchroner
Datenaustausch
Bei asynchronem Datenaustausch
hat man ein Maximum an Flexibilität und Parallelität.
Allerdings ist eine Pufferung der Daten notwendig. Ebenfalls
ein Nachteil ist, dass komplexe Programme schwierig zu testen
sind.
Synchroner Datenaustausch erlaubt
einfache und verifizierbare Programme, hat aber den Nachteil
der Einschränkung der Parallelität. Es ist, wie
schon oben erwähnt, keine Pufferung notwendig.
7. Verbindungslose- und
verbindungsorientierte Kommunikation
Kommunikation wird in verbindungsorientierte
und verbindungslose Kommunikation unterteilt. Verbindungsorientierte
Kommunikation ist zuverlässig. Verbindungslose Kommunikation
ist im Prinzip unzuverlässig, kann aber auch zuverlässig
gemacht werden.
7.1 Verbindungslose Kommunikation
Bei der verbindungslosen Kommunikation
werden die Nachrichten als isolierte Einheiten übertragen.
Es findet keine Flusskontrolle statt, d.h. Einheiten können
sich überholen. Wie schon erwähnt ist verbindungslose
Kommunikation meist unzuverlässig, aber auch zuverlässige
Datagramme sind möglich.
Wie sieht ein Protokoll bei unzuverlässigen
Datagrammen aus?
Es sind einfachste Protokolle. P1 sendet P2 eine Nachricht.
Diese Nachricht kann verloren gehen, es können Duplikate
entstehen, die Reihenfolge kann verändert werden, die
Daten können unterwegs modifiziert werden. Weder P1 noch
P2 unternehmen etwas, um dies zu ändern.
Wie sieht ein Protokoll bei zuverlässigen
Datagrammen aus?
Hier sind komplexere Protokolle notwendig. Wie kann man Verlust,
Modifikation und Duplikate und Folgefehler erkennen?
Verlust lässt sich dadurch erkennen, dass ein ACK für
jedes übertragene Datagramm fällig wird. P1 sendet
eine Nachricht und startet einen Timer. Nun gibt es zwei Möglichkeiten,
nämlich das die Nachricht selbst verloren geht oder ACK
nicht ankommt. Bei beiden Möglichkeiten sendet P1 nach
Ablauf des Timers die Nachricht nochmals.
Falls ACK verlorengegangen ist, muss P2 Duplikate erkennen.
Dies kann mittels Nachrichten-IDs gelöst werden.
Modifikation wird dadurch erkannt, dass eine Prüfsumme
berechnet wird. Weicht sie vom erwarteten Wert ab, ist ein
Übertragungsfehler passiert.
Folgefehler kann man mittels fortlaufendender Nummerierung
erkenn, z.B. auch durch fortlaufende Nachrichten-IDs.
7.2 Verbindungsorientierte
Kommunikation
Bevor eine verbindungsorientierte
Kommunikation erfolgen kann, muss zuerst eine Verbindung aufgebaut
werden. Nach dem Datentransfer wir die Verbindung wieder abgebaut.
Verbindungsaufbau, Datentransfer und Verbindungsabbau wird
3-phasige Interaktion genannt.
Beim Verbindungsaufbau kann die
Qualität des Dienstes ausgehandelt werden. (Quality of
Service). Das sind z.B. Merkmale wie Durchsatz, Verzögerung
oder Fehlerwahrscheinlichkeit.
Bei einer verbindungsorientierten
Kommunikation wird zuverlässige Kommunikation in beide
Richtungen betrieben, d.h. kein Verlust, keine Duplikate,
keine Modifikation. Keine Folgefehler, d.h. Flusskontrolle
findet ebenfalls statt. Dies alles erfordert eine vergleichsweise
komplexe Protokolle.
Es sind zusätzliche Primitive
für den Verbindungsaufbau und -abbau nötig:
connect: Senden eines Verbindungswunsches
listen: Empfangen eines Verbindungswunsches
accept: Akzeptieren eines Verbindungswunsches
reject: Ablehnen eines Verbindungswunsches
disconnect: Abbau einer Verbindung usw.
Wichtige Protokollelemente:
Verbindungsaufbau durch das Three-Way-Handshake.
Verbindungsabbau
Fehlerkontrolle: Positive Acknowledgement
and Retransmit (PAR)
Sequenzkontrolle durch Sequenznummern
Fehlererkennung durch Prüfsumme
(z.B. CRC)
Flusskontrolle durch Fenstermechanismus
oder Credits
Zusätzliche Hinweise:
Ein Beispiel für den Fenstermechanismus
ist Sliding Windows.
ACK sind Bestätigungen.
NAK sind negative Bestätigungen.
Ein NAK kann z.B. von P1 an P2 gesendet werden, um anzudeuten,
dass zwar die Dateneinheit empfangen wurde aber die Fehlererkennung
einen Fehler festgestellt hat.
NAK dient hauptsächlich der Beschleunigung. Z.B. könnte
Prozess P2 auch so lange warten und kein ACK senden, bis P1
das fehlerhafte Packet nochmals sendet.
Falls ein Protokoll NAK nicht
implementier hat, so spricht man von Fehlerkontrolle mittels
PAR. Es gibt nur bei erfolgreichem Empfangen ein ACK, d.h.
der empfangende Prozess wartet bis Timeout beim Sender auftritt
und er ein erneutes Senden veranlasst.
Man spricht von Three-Way-Handshake,
falls der Verbindungsaufbau in drei Schritten erfolgt, so
wie dies beim Aufbau einer TCP-Verbindung der Fall ist.
7.3 Verbindungslose- vs.
verbindungsorientierte Kommunikation
Argumente für verbindungsorientierte
Kommunikation
Einfaches und mächtiges
Paradigma. Es vereinfacht die höheren Schichten und führt
somit zur Entlastung der Endsysteme. Verbindungslose Kommunikation
ist für ein breites Spektrum von Anwendungen geeignet.
Argumente für (unzuverlässige)
verbindungslose Kommunikation
Sie hat hohe Flexibilität
und geringe Komplexität. Für einige Anwendungen
(z.B. Echtzeitanwendungen, digitale Sprachübertragung)
ist hohe Performance wichtiger als fehlerfreie Übertragung.
Falls nur eine relativ kurze Interaktion gewünscht wird,
so ist der Kostenanteil für Auf und Abbau von Verbindungen
hoch. "End-to-End-Arguments".
Was bedeutet "End-To-End-Arguments"?
8. End-to-End-Argumente
In geschichteten Systemen kann
die Realisierung einer Funktion in unteren Schichten überflüssig
sein, oder ihre Realisierung verursacht hohe Kosten.
Bei unzuverlässiger Kommunikation
können Fehler erst in oberen Schichten entdeckt und behandelt
werden. Zuverlässige Kommunikation ist teuere Kommunikation.
Der Grund liegt darin, dass End-to-End Recovery trotzdem notwendig
ist, obwohl viele Funktionen in unteren Schichten realisiert
werden. Dazu zählen z.B. Übertragungsfehler oder
Duplikatserkennung. Die Duplikatsunterdrückung im Server
z.B. erkennt und unterdrückt auch Duplikate des Transportsystems.
Z.B. kann auch eine End-to-End Verschlüsselung die Verschlüsselung
auf der Transport-Ebene überflüssig machen.
Was spricht gegen End-to-End-Argumente?
Wenn bestimmte Funktionen in
unteren Schichten realisiert werden, werden Fehler entdeckt.
Das spart Bandbreite und CPU- und Pufferressourcen.
Die Frage, welche Funktionen
wo realisiert werden sollen, hängt von der Art und Topologie
des Netzwerkes ab. Außerdem spielen Zuverlässigkeitsanforderungen
der Anwendungen eine wichtige Rolle.
Man kann einen Kompromiss schließen.
Das Transportsystem unterstützt zwei Dienstklassen, nämlich
einen allgemeinen zuverlässigen Dienst und einen effizienten
unzuverlässigen Dienst.
9. Quellen
[1] Skript Grundlagen Verteilte
Systeme; Prof. Dr. Kurt Rothermel - Abteilung Verteilte Systeme
an der Universität Stuttgart
|