|
RPC
- Remote Procedure Call
ÜBERSICHT
1. Definition und Funktionsweise
des RPC
2. Ablauf eines RPC
3. Aufgaben der Prozedurrümpfe (Stubs)
4. RPC-Semantiken
5. RPC-Protokolle
6. Waisenbehandlung
7. Quellen
1.
Definition und Funktionsweise des RPC
RPC ist ein Mechanismus um verteilte
Anwendungen auf Basis des Client/Server-Modells zu realisieren.
Neben dem Client/Server gibt es zwei weitere Kooperationsformen,
nämlich Produzenten/Konsumenten-Systeme und das Pipeline-Modell.
Prozesse kooperieren, um ein gemeinsames Ziel zu erreichen.
Client/Server-Modell
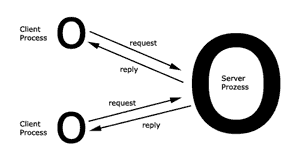
Der Server bietet seinen Service einer Menge a priori unbekannter
Clients an. Service bezeichnet die Software-Instanz, die auf
einer oder mehreren Maschinen ausgeführt wird. Der Server
ist eine Maschine, die Service-Software ausführt. Der
Client ist der Nutzer eines Services.
Produzenten/Konsumenten-Systeme

Der Konsument nimmt Daten auf, die vom Produzenten erzeugt
wurden. Hier genügt ein unidirektionaler Kanal.
Pipeline-Modell
Eine Pipeline kann man sich als ein unidirektionalen Kanal
vorstellen.
2. Ablauf eines RPC
3. Aufgaben der Prozedurrümpfe
(Stubs)
3.1 Binden von Clients an
Server
Binden ist die Zuordnung eines
Clients an einen Server. Der Server muss die vom Client gewünschte
Prozedur anbieten. Beim Binden unterscheidet man zwei Arten,
nämlich das statische Binden und das dynamische Binden.
Statisches Binden
Beim statischen Binden geschieht das Binden beim Übersetzen
des Clientprogramms. Der Client-Stub identifiziert den Server
mittels einer Adresse. Diese Art des Bindens hat den Vorteil,
dass es kein Overhead zur Laufzeit gibt. Ein großer
Nachteil ist aber, dass keine dynamische Server-Rekonfiguration
möglich ist. Auch ist der Einsatz von mobilen Servern
nicht möglich. Sämtliche Server müssen zur
Zeit der Übersetzung bekannt sein.
Dynamische Binden
Beim dynamischen Binden gibt es Unterschiede in der Wahl des
Bindezeitpunktes und der Art des Bindevorgangs.
Das Binden kann zu Beginn des
Programmablaufs gemacht werden. Dies hat den Vorteil, das
ein Bindevorgang pro entfernter Prozedur nötig ist. Dabei
spielt die Anzahl der Aufrufe der entfernten Prozedur keine
Rolle. Der Nachteil ist, dass keine dynamische Anpassung an
den aktuellen Systemzustand während der Programmausführung
möglich ist.
Geschieht das Binden erst beim Aufruf der entfernten Prozedur,
so hat es des Vorteil, dass eine dynamische Anpassung an den
Systemzustand möglich ist. Dem gegenüber steht der
Nachteil des mehrfachen Bindens pro entfernter Prozedur.
Auf welche Art kann ein Bindevorgang
durchgeführt werden? Es gibt die Möglichkeit der
Zuhilfenahme eines Directory-Dienstes oder mittels Broadcast-Aufrufen.
Einen Directory-Dienst kann man
sich als Dienst vorstellen, der sämtliche Server mit
den angebotenen Diensten verwaltet. Falls ein Client einen
RPC startet, so wird zuerst im Directory-Dienst nachgeschaut,
welcher Server den gewünschten Dienst anbietet. Als Antwort
auf die Anfrage wird dem Client die Adresse des Servers übergeben.
Erst dann kann auf der Client-Seite das Binden gemacht werden.
Diese Art des Bindevorgangs kann auch in größeren
Systemen eingesetzt werden, hat aber den Nachteil, dass der
Directory-Dienst sehr zuverlässig und leistungsfähig
sein muss.
Falls kein Directory-Dienst gewünscht
wird, so bietet sich die Möglichkeit mittels Broadcast-Aufrufen
den Server zu finden, der den gewünschten Dienst anbietet.
Dabei startet der Client einen Broadcast-Aufruf. Alle Server
antworten mit den zur Verfügung gestellten Diensten und
ihren Adressen. Der Client entscheidet sich für den Server,
der den benötigten Dienst zur Verfügung stellt.
Diesen kann er mittels der Adresse ansprechen. Broadcast-Aufrufe
erfordern, dass alle Server den Aufruf bearbeiten. Auch sind
sie nur in lokalen Netzen praktikabel.
3.2 Transparente Kommunikation:
Transport-Mechanismus (z.B. TCP, UDP), Datenrepräsentation
und Sicherheit (Verschlüsselung, Authentifizierung)
Auf welche Art und Weise (welches
Protokoll, Art der Verschlüsselung, Authentifizierung)
die Kommunikation zwischen Client und Server stattfindet ist
Sache des Client-Stubs. Z.B. baut SUN RPC auf TCP und UDP
auf.
Idealerweise sollte der Aufruf
von eine entfernten Prozedur das gleiche Verhalten haben wie
der Aufruf einer lokalen Prozedur. Man unterscheidet zwischen
call-by-value und call-by-reference Parameteraufrufen.
3.3 Kodierung (Marshalling)
und Dekodierung (Unmarshalling) von Argument- und Ergebnisparametern
der entfernten Prozedur
call-by-value
function inc1(i: integer) : integer;
begin
i:= i+1;
return (i)
end;
Aufruf z:=inc1(x);
Client-Stub: Bei einem Aufruf
der entfernten Prozedur inc1, wird der Wert des Variable x
als Argument in die Nachricht an den Server kopiert.
Server-Stub: Der Server-Stub kopiert die Nachricht in eine
Variable i
Die Prozedur wird ausgeführt.
Server-Stub: Server-Stub kopiert aus Variable i Ergebnis in
Nachricht an Client-Stub.
Client-Stub: Kopiert Ergebnis aus Nachricht in Variable z
call-by-reference, Mögliche
Realisierung durch Call-by-Copy / Restore-Ansatz
procedure inc2 (var i : integer);
begin
i:=i+2;
end;
Aufruf inc2(x);
Client-Stub: Bei einem Aufruf
der entfernten Prozedur inc2, wird Variable x als Argument
in Nachricht an den Server kopiert.
Server-Stub: Der Server-Stub kopiert Argument aus Nachricht
in Stub-Variable und übergibt der Prozedur Pointer auf
Stub-Variable.
Die Prozedur wird ausgeführt.
Server-Stub: Kopiert wird der Wert der Stub-Variable als Ergebnis
in Nachricht an den Client.
Client-Stub: Kopiert Ergebnis aus Nachricht in Variable x
Allerdings gibt es Probleme mit
dem Call-by-Copy / Restore Ansatz. Falls es bei einem entfernten
Prozeduraufruf unterschiedliche Kopien für eine Referenzvariable
gibt, so unterscheiden sich die Ergebnisse bei einer lokalen
und entfernten Ausführung. Kurz: Probleme entstehen,
falls zwei oder mehr Parameter das gleiche Objekt referenzieren.
Eine alternative Realisierung
ist der Zugriff des Servers auf den entfernten Parameterwert
auf der Clientseite. Das verursacht allerdings einen hohen
Overhead.
Als Fazit kann man festhalten,
dass Call-by-Value Parameterübergabe einfach und effizient
zu realisieren sind. Call-by-Reference und Pointer-Parameter
sind problematisch bzw. ineffizient. Deshalb erlauben viele
RPC-Systeme nur Call-by-Call-Value-Parameter.
3.4 Fehlerbehandlung (Kommunikationsfehler,
Clientfehler und Serverfehler)
Es können folgende Fehler
auftreten:
Fehler 1: RPC Auftrag nicht korrekt
übertragen oder geht verloren.
Fehler 2: RPC Ergebnis nicht
korrekt übertragen oder geht verloren.
Fehler 3: Server kann Prozedur
nicht beenden, z.B. durch Rechnerausfall oder Software-Fehler.
Fehler 4: Client wird während
des RPCs abgebrochen, z.B. durch Rechnerausfall oder Software-Fehler.
Es gibt drei Möglichkeiten
wie der Client-Stub im Falle des Ausbleibens einer Antwort
reagiert.
1: Als erstes kann der Client-Stub
auf die Antwort warten, ohne etwas zu unternehmen. Damit ist
der Client permanent blockiert. Die Prozedur wird entweder
irgendwann ausgeführt oder nicht.
2: Der Client-Stub benutzt Timeout-Mechanismus.
Falls es innerhalb der eingestellten Zeit zu keiner Ausführung
der Prozedur kommt, gibt der Client-Stub eine Fehlermeldung
an den Client weiter.
3: Der Client-Stub benutzt Timeout-Mechanismus.
Falls es innerhalb der eingestellten Zeit zu keiner Ausführung
der Prozedur kommt, sendet der Client-Stub den Auftrag erneut
an Server. Falls der Server Duplikate (von Anfragen) erkennt,
wird die Prozedur nur einmal ausgeführt, falls nicht
>=1.
Ohne Fehler garantiert jedes
RPC-System, dass eine entfernte Operation genau einmal ausgeführt
wird. Im Fehlerfall können unterschiedliche RPC-Systeme
ein unterschiedliches Verhalten aufweisen, wie oben beschrieben.
RPC-Semantiken beschreiben, wie
sich ein RPC-System im Fehlerfall verhält.
4. RPC-Semantiken
4.1
Maybe
Ein Aufruf wird nicht oder höchstens einmal ausgeführt.
Der Client erhält im Fehlerfall eventuell keine Information
über den Status des Aufrufs.
4.2
At-Least-Once
Ein Aufruf wird mindestens einmal ausgeführt, d.h. Mehrfachausführungen
sind möglich.
4.3
At-Most-Once
Ein Aufruf wird genau einmal ausgeführt. Jedoch gibt
es Einschränkungen bei Systemfehlern. D.h. es wird keine
Garantie für eine Ausführung gegeben, aber es wird
garantiert, dass es keine Mehrfachausführung gibt.
4.4
Exactly-Once
Der Aufruf wird genau einmal ausgeführt, es gibt keine
Einschränkung bei Systemfehlern.
5. RPC-Protokolle
Ein RPC-Protokoll ist die Realisierung
einer RPC-Semantik. Unter 4. wurden RPC-Semantiken vorgestellt.
Hier soll näher darauf eingegangen werden, wie die geforderten
Eigenschaften der jeweiligen RPC-Semantik erreichen lässt.
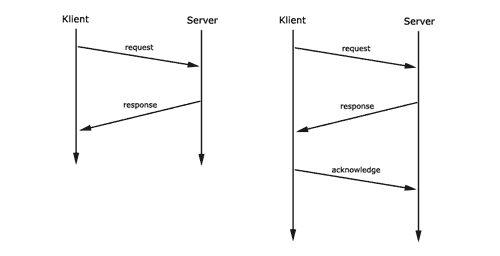
Es gibt zwei unterschiedliche
Protokollklassen. Request/ Response (RR) und Request/ Response/
Acknowledge (RRA)
5.1 Maybe
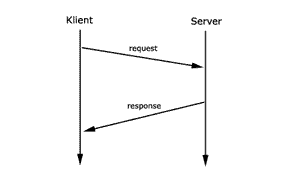
Der Client-Stub sendet einen
Auftrag und startet Timer. Falls Timeout oder ein Fehler auftritt,
bevor die Antwort eintrifft, wird eine Fehlermeldung (Exception)
an den Client weitergegeben.
Der Server-Stub erkennt keine Duplikate. Er sendet die Antwort
nach Ausführung der Prozedur.
Was passiert, wenn request unterwegs verloren geht? Der Client-Stub
wartet bis Timeout und gibt Exception an den Client weiter.
Was passiert, wenn response verloren geht? Der Client-Stub
wartet bis Timeout und gibt Exception an den Client weiter.
Falls es zu keinem Fehler kommt, wird der Aufruf höchstens
einmal ausgeführt. Bei einem Fehler wird der Aufruf nicht
ausgeführt. Somit ist die obere Forderung erfüllt.
5.2
At-Least-Once
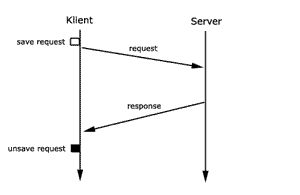
Der Client-Stub speichert den Auftrag in einem flüchtigen
Speicher. Falls es zu einem Timeout kommt, sendet er Auftrag
periodisch an den Server, bis eine Antwort eintrifft. Der
Auftrag wird aus dem flüchtigen Speicher gelöscht,
wenn die Antwort eintrifft.
Der Server-Stub erkennt keine Duplikate und sendet Antwort
nach Ausführung der Prozedur an Client-Stub.
Was passiert, wenn request verloren geht? Nach Timeout sendet
der Client-Stub die Anfrage nochmals. Dies wird so oft wiederholt,
bis eine Antwort eintrifft.
Was passiert, wenn response verloren geht? Nach Timeout sendet
der Client-Stub die Anfrage nochmals. Dies wird so oft wiederholt,
bis eine Antwort eintrifft.
Falls request verloren geht, wird die Anfrage nur einmal ausgeführt.
Falls allerdings response verloren geht, wird die Anfrage
mehrmals ausgeführt. Der Server erkennt nämlich
keine Duplikate.
Die Forderung ist erfüllt. Aufruf wird mindestens einmal
ausgeführt, aber Mehrfachausführungen sind möglich.
5.3 At-Most-Once
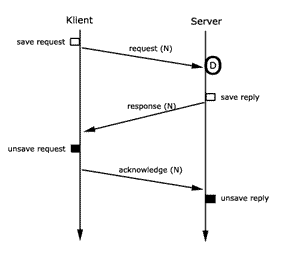
Der Unterschied zu At-Least-Once
ist, dass der Server die Antwort in einen flüchtigen
Speicher schreibt und sie danach erst an den Client-Stub sendet.
Der Server-Stub ist in der Lage Duplikate auf der Basis von
Auftrag-Id zu erkennen und führt eine Anfrage genau einmal
durch. Nur wenn ack beim Server einkommt, wird das Ergebnis
der Anfrage aus dem Speicher gelöscht. Wenn nicht, sendet
der Server-Stub die Antwort periodisch bis ack eintrifft.
Was passiert, wenn request verloren geht? Nach Timeout sendet
Client-Stub die Anfrage nochmals. Die wird periodisch wiederholt,
bis eine Antwort eintrifft.
Was passiert, wenn response verloren geht? Nach Timeout sendet
Client-Stub die Antrage erneut. Durch den Auftrag-Id erkennt
der Server-Stub das Duplikat. Die gespeicherte Antwort wird
ausgelesen und erneut gesendet. Damit ist die Forderung erfüllt,
dass die Anfrage genau einmal berechnet wird.
Was passiert, wenn ack verloren geht? Server-Stub sendet die
Antwort periodisch, bis ack eintrifft. Weitere Frage: Wie
weiß der Client-Stub, falls er die Anfrage nach Empfang
von response (d.h. ack ging verloren) löscht, ob er ein
ack einfach so, nach einem erneuten Empfang von response,
senden soll? Eine Möglichkeit wäre, dass der Client-Stub
die acks speichert und erst nach einer gewissen Zeit löscht.
Die Forderung, dass der Aufruf
genau einmal ausgeführt wird, ist somit erfüllt.
Bei Client- und Server-Fehlern kann die Ausführung nicht
garantiert werden.
5.4 Exactly-Once
Dieses Protokoll ist wie bei
At-Most-Once, außer das die Aufträge und Antworten
auf stabilen Speicher geschrieben werden. Save und Unsave
sind atomare Operationen. Ein Server-Fehler vor save macht
alle Änderungen der Prozedur rückgängig.
6. Waisenbehandlung
Ein Abbruch von Clients kann
zu Waisen (Orphans) führen. Ein Waise ist ein aktiver
Server ohne wartenden Clients. Waisen bedeuten Verschwendung
von Ressourcen, sowie die unnötige Sperrung von Betriebsmitteln.
Außerdem können die Nachrichten von verwaisten
Servern weiderangelaufene Clients stören. Es gibt einige
Ansätze, um diese Probleme zu lösen.
6.1 Extermination
Der Client-Stub schreibt alle
Adressen der aktiven Server in einen stabilen Log. Nach Wiederanlauf
des Client sendet dieser "abort-server"-Nachrichten
an alle Server im Log.
Bei diesem Ansatz führt der Client die Waisenentdeckung
durch. Außerdem führt häufiges Schreiben auf
stabilem Speicher zu einem hohen Overhead. Allerdings kann
eine Netzpartitionierung den Server unerreichbar machen.
6.2 Expiration
Bei diesem Ansatz bekommt der
Server eine genaue Zeit zur Auftragsbearbeitung. Läuft
die Zeit ab, so muss der Server die Verlängerung explizit
beantragen. Wird die Verlängerung nicht gewährt
oder nicht beantwortet, so wir der Auftrag abgebrochen.
Hier übernimmt der Server die Waisenentdeckung. Eine
Netzwerkpartitionierung wird hier toleriert, d.h. falls der
Client und der Server sich nicht mehr erreichen können,
erfolgt trotzdem ein Abbruch der Auftrages auf dem Server.
Außerdem gibt es hier einen erhöhten Aufwand durch
die Anfrage-Nachrichten.
6.3 Drakonische Inkarnation
Die Zeit wird in Epochen eingeteilt
und sequentiell durchnumeriert. Das System hält die Nummer
der aktuellen Epoche auf stabilem Speicher fest. request-
und response-Nachrichten enthalten die Nummer der aktuellen
Epoche. Nach einem Crash des Client startet dieser nach dem
Wiederanlaufen eine neue Epoche mit new epoche und wird mittels
Broadcast new epoche an alle Server gesendet. Die empfangenden
Server werden abgebrochen. Falls ein Server ein request aus
einer neuen Epoche empfängt, so wird dieser ebenfalls
abgebrochen. Es gibt also zwei Möglichkeiten um eine
Server zum Abbruch zu bringen.
Wie merkt der angefahrene Client, dass er kurz zuvor zusammengebrochen
war? Nach dem Anfahren vergleicht der Client seine aktuelle
Epochennummer mit der Nummer auf dem stabilem Speicher.
Die Waisenentdeckung übernehmen Client und Server. Ein
großes Nachteil der drakonischen Inkarnation ist, dass
bei einem Wechsel der Epoche alle Server abgebrochen werden.
6.4 Behutsame Inkarnation
Der Unterschied zur drakonischen
Version ist hier, dass beim Beginn einer neuen Epoche der
Server überprüft, ob er tatsächlich Waise ist.
Das hat den Vorteil, dass nur Waise abgebrochen werden.
7. Quellen
[1] Skript Grundlagen Verteilte
Systeme; Prof. Dr. Kurt Rothermel - Abteilung Verteilte Systeme
an der Universität Stuttgart
|